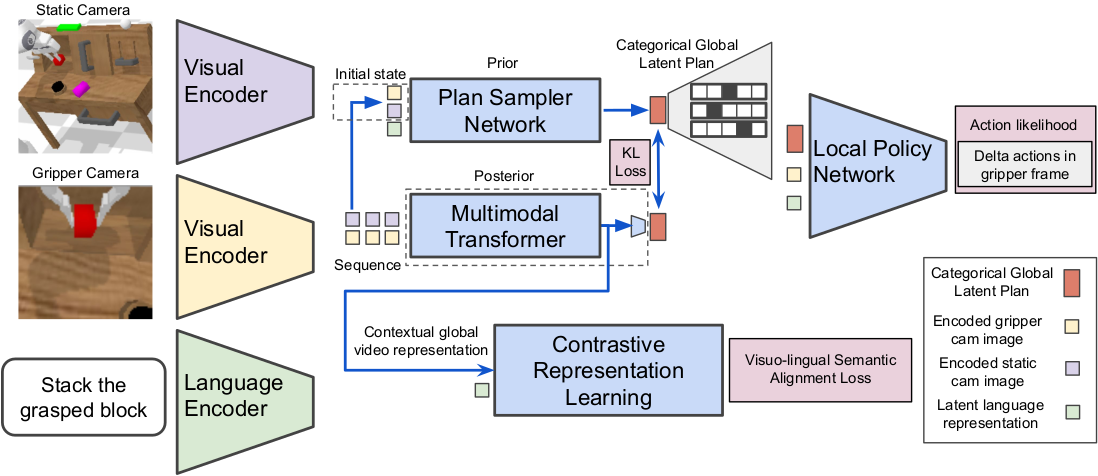
A long-standing goal in robotics is to build robots that can perform a wide range of daily tasks from perceptions obtained with their onboard sensors and specified only via natural language. While recently substantial advances have been achieved in language-driven robotics by leveraging end-to-end learning from pixels, there is no clear and well-understood process for making various design choices due to the underlying variation in setups. In this paper, we conduct an extensive study of the most critical challenges in learning language conditioned policies from offline free-form imitation datasets. We further identify architectural and algorithmic techniques that improve performance, such as a hierarchical decomposition of the robot control learning, a multimodal transformer encoder, discrete latent plans and a self-supervised contrastive loss that aligns video and language representations.
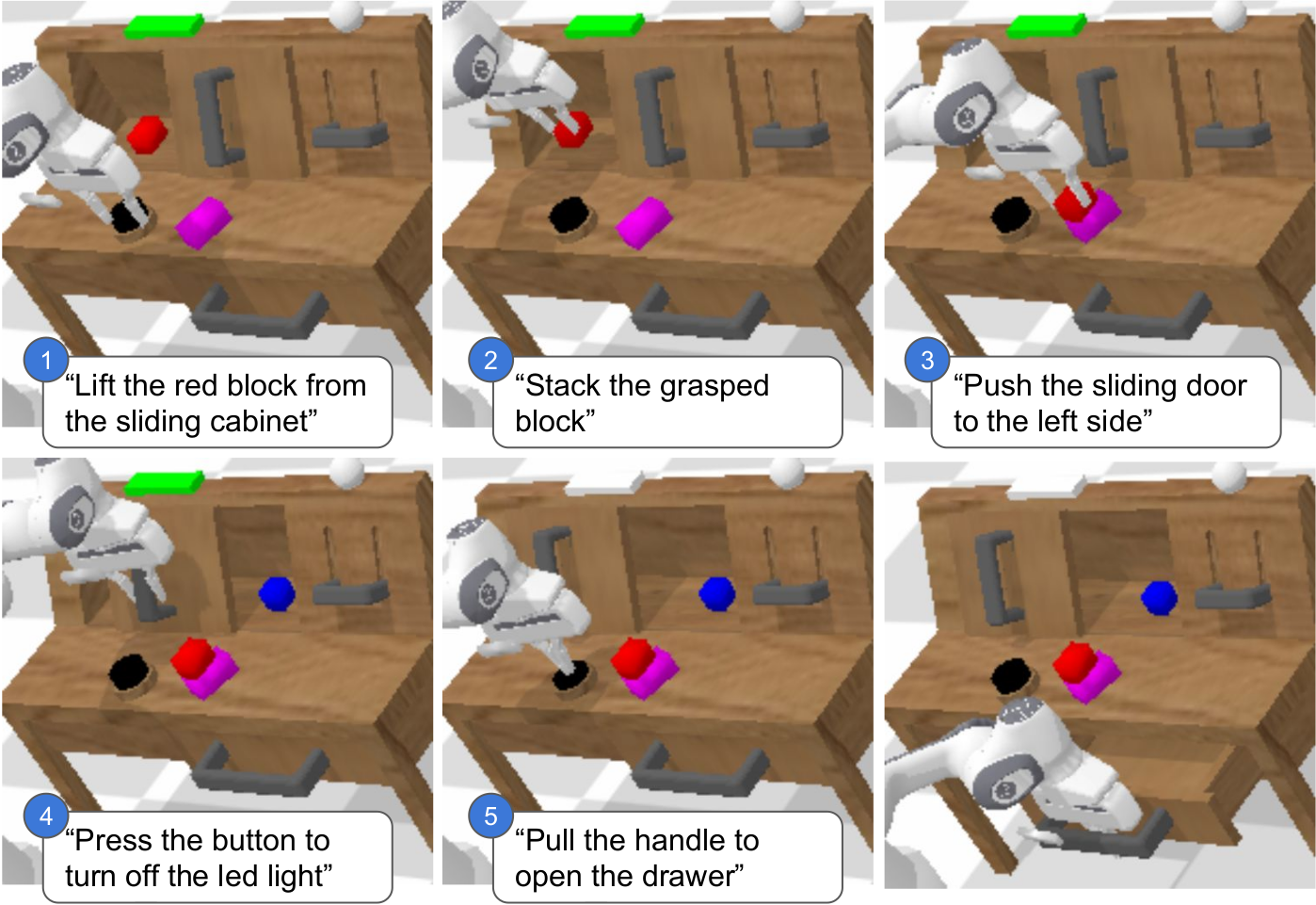
By combining the results of our investigation with our improved model components, we are able to present a novel approach that significantly outperforms the state of the art on the challenging language conditioned long-horizon robot manipulation CALVIN benchmark.